Nel novembre 2022, OpenAI ha trasformato il panorama dell’intelligenza artificiale lanciando ChatGPT, un sistema chatbot avanzato basato sull’architettura Transformer, introdotto da Google nel 2017 nell’influente documento “L’attenzione è tutto ciò che serve”. Questa architettura ha rivoluzionato il campo dell’elaborazione del linguaggio naturale introducendo il meccanismo dell’attenzione, consentendo ai modelli di identificare complesse relazioni contestuali tra le parole, ottenendo risposte più coerenti e pertinenti.
Attualmente la piattaforma conta 100 milioni di utenti e il mercato dell’intelligenza artificiale continua ad espandersi, con nuove forme e applicazioni che emergono continuamente. Questo articolo si propone di fare chiarezza sul panorama del mercato AI nello scenario post-ChatGPT, evidenziando le innovazioni, i trend e le opportunità emerse dal lancio di questo rivoluzionario sistema.
La divulgazione di modelli linguistici su larga scala (LLM)
ChatGPT è classificato come Large Language Models (LLM), una tecnologia di modelli addestrati con grandi quantità di dati per generare risposte in linguaggio naturale. Con la rapida adozione di utenti con profili diversi, anche altre grandi aziende hanno iniziato a posizionarsi sul mercato, portando il settore LLM a prendere forma ed espandersi rapidamente.
L’anno successivo, nel 2023, Google ha lanciato Bard, un chatbot basato sul proprio modello che utilizza anch’esso l’architettura Transformer. Successivamente sono emersi altri modelli più avanzati, come Gemini, sempre di Google, Claude, di Anthropic, Ernie, di Baidu, e Grok, di Elon Musk. Tutti questi modelli sono proprietari e sono stati sviluppati con l’obiettivo di conquistare una quota di mercato. Tuttavia, a causa delle differenze nelle caratteristiche dei modelli e delle diverse richieste del mercato, ognuno di essi finì per specializzarsi in nicchie e applicazioni diverse.
Ad esempio, Claude è stato sviluppato ponendo una forte enfasi sulla calibratura dell’etica delle risposte, cercando di evitare qualsiasi influenza indebita sugli utenti. Ernie, a sua volta, è stato progettato per operare all’interno delle applicazioni cinesi, garantendo il rispetto delle normative locali ed evitando interferenze politiche esterne. Grok è stato integrato nella nuova applicazione di Elon Musk, X (ex Twitter), con l’obiettivo di fornire risposte e interazioni direttamente sulla piattaforma.
Iniziative Open Source
Un altro importante player, Meta (ex Facebook), ha deciso di andare nella direzione opposta al mercato dell’IA proprietaria, investendo nella community con il lancio di LLaMA (Large Language Model Meta AI), un modello open source. Riconoscendo le sfide legate alla raccolta di una grande massa di dati di addestramento, come quelli utilizzati in ChatGPT, e gli elevati costi di elaborazione dell’addestramento di modelli su larga scala, Meta ha rilasciato una versione specifica, Meta LLaMA 3.1, con una base addestrata e precostruita disponibile al pubblico.
Questo approccio ha consentito agli sviluppatori di avere accesso diretto al codice sorgente e di poter addestrare le proprie versioni personalizzate del modello. L’iniziativa ha favorito l’emergere di una serie di modelli derivati, incoraggiando la collaborazione e il progresso delle tecnologie di intelligenza artificiale in ambienti aperti. In questo modo, Meta ha contribuito a creare una comunità di sviluppo più inclusiva e innovativa, ampliando l’accesso alle tecnologie IA avanzate.
Le alternative open source hanno rapidamente guadagnato terreno. Modelli come Dolly, sviluppato da Databricks, e Mistral sono stati introdotti come opzioni convenienti per gli sviluppatori che necessitavano di LLM flessibili e personalizzabili, senza i costi elevati dei modelli chiusi e proprietari. Ciò ha consentito ad aziende e ricercatori di sviluppare LLM su misura per le loro esigenze specifiche, consentendo usi più mirati e specializzati.
Sebbene i modelli proprietari siano spesso progettati per usi generici, molte aziende con esperienza in aree specifiche scelgono di addestrare i propri modelli per evitare di esporre dati sensibili a terzi, come OpenAI. Il mercato open source ha quindi ottenuto il sostegno di queste aziende, che spesso creano i propri data center AI e formano modelli unici per soddisfare le loro esigenze di sicurezza e specializzazione.
Il ruolo del Fine-Tuning: incorporare conoscenze specializzate
Una delle principali innovazioni nell’uso dei LLM è la possibilità di messa a punto. Questo processo consiste nell’utilizzare il database già addestrato, come GPT-4 o LLaMA 3.1, con dati aggiuntivi specifici per una particolare applicazione. È un approccio particolarmente vantaggioso in contesti che richiedono terminologia specializzata o conoscenze approfondite, come nel settore sanitario, giuridico o finanziario. Con la messa a punto, il modello “apprende” modelli e vocaboli specifici del settore, diventando più accurato ed efficiente quando risponde a domande o esegue attività relative a quel dominio.
Aziende e organizzazioni hanno richiesto molti servizi di fine tuning, afferma Gustavo Zaniboni, CAIO di Ananque, “il fine tuning consente di addestrare modelli linguistici con dati interni, creando sistemi di intelligenza artificiale che comprendono meglio i processi e i contesti specifici dell’istituzione”. Questa tecnica aumenta significativamente la pertinenza delle risposte e trasforma i LLM in strumenti pratici e potenti per uso commerciale, ampliando il loro valore nelle applicazioni aziendali.
Contesto, token e RAG
Uno dei parametri che influiscono direttamente sulla qualità delle risposte generate dai modelli linguistici su larga scala (LLM) è la finestra di contesto, che consente al modello di conservare informazioni rilevanti sull’argomento discusso durante la conversazione. Questo contesto funge da memoria a breve termine, consentendo al LLM di avere una comprensione più ricca e accurata della query. All’aumentare del contesto, aumenta anche il numero di token (unità di elaborazione del linguaggio) utilizzati, il che richiede più risorse computazionali e, di conseguenza, rende l’elaborazione più costosa.
Per le aziende che forniscono il servizio, più token significano più profitto, tuttavia, per l’utente, caricare un database di token specializzato è diventato sempre più costoso. Cercando di riunire il meglio per entrambe le parti, si iniziò a utilizzare la tecnologia intermedia.
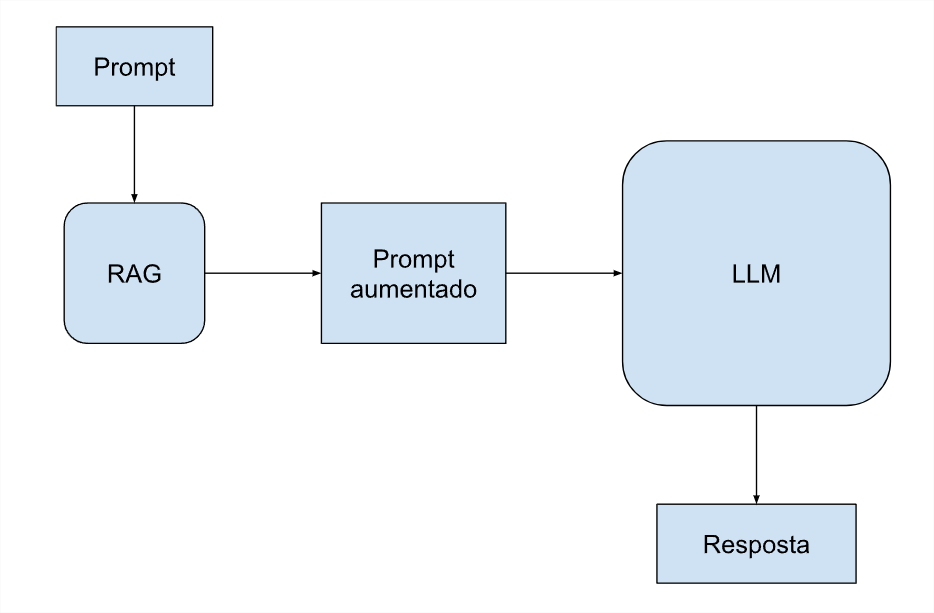
Recupero delle informazioni con RAG: riunire il meglio di entrambi i mondi
La tecnologia intermedia serve per una maggiore generazione tramite il recupero dei dati e in inglese si chiama RAG (Retrieval-Augmented Generation). Combina modelli linguistici con meccanismi di recupero delle informazioni. L’approccio RAG consente al modello di accedere e incorporare dati specifici direttamente nel prompt, interrogando i database senza la necessità di inviare tutti i token con ogni richiesta. Questo approccio ottimizza i costi, poiché riduce il volume di dati elaborati per query, pur mantenendo l’accuratezza e la pertinenza delle risposte.
La tecnica RAG risolve anche un altro problema, il fatto che LLM dispone di un database pre-addestrato e statico, che finisce per diventare obsoleto nel tempo. Il database RAG può includere dati esterni e mantenere le conoscenze più attuali e rilevanti più a lungo, fino allo svolgimento di una nuova importante formazione.
È importante notare che molti professionisti specializzati credono ancora che, per privati o utenti finali, ChatGPT sia ancora il miglior LLM per la maggior parte delle attività, come affermato da Elisa Terumi, PhD in IT presso PUC-P. “I modelli proprietari, come quelli della famiglia GPT-4, sono generalmente più grandi e robusti, addestrati su volumi di dati più grandi e con un numero maggiore di parametri. Vengono inoltre sottoposti a tecniche di ottimizzazione avanzate, come l’apprendimento per rinforzo con feedback umano (RLHF), migliorando la loro capacità di generare risposte più naturali e contestualizzate. In questo modo, i modelli della famiglia GPT presentano generalmente prestazioni superiori in molti compiti.”
Tuttavia, per l’uso aziendale, le sfide sono diverse e riguardano aspetti come la sensibilità dei dati e gli elevati costi di elaborazione e infrastruttura Internet. Questi problemi richiedono soluzioni specifiche e approcci strategici per garantire sicurezza, efficienza e sostenibilità economica.
Applicazioni aziendali con Small Language Model
Un’azienda che vuole offrire un servizio specializzato con i propri dati può trarre vantaggio dall’utilizzo di SLM (Small Language Model). “Questo approccio sta crescendo nel mercato”, afferma Danilo Santos, fondatore di Servicedesk Brasil, spinto principalmente dal numero crescente di specialisti e consulenti di IA. Per proteggere i dati sensibili e ridurre significativamente i costi delle query, molte aziende scelgono di assumere un professionista dell’intelligenza artificiale per installare un LLM nel proprio data center e addestrarlo da zero.
Generalmente il database di queste aziende non è così ampio come quello utilizzato dalle grandi aziende tecnologiche, motivo per cui la tecnica si chiama SLM (Small anziché Large). Sebbene questi modelli coinvolgano meno dati, sono in grado di fornire informazioni pertinenti e accurate, anche se mancano della fluidità del linguaggio di chat presente nei LLM più robusti, progettati per soddisfare le esigenze dei singoli utenti finali. Questa strategia consente alle aziende di sfruttare in modo efficace le proprie informazioni interne garantendo al tempo stesso la sicurezza e la riservatezza dei dati.
Panoramica sull’intelligenza artificiale
L’intelligenza artificiale è sicuramente sotto i riflettori dopo il lancio di ChatGPT. Gli LLM stanno avendo un impatto significativo in tutti i settori dell’industria e dei servizi. Grazie al suo enorme potenziale, gli investimenti in quest’area sono cresciuti rapidamente, determinando una costante evoluzione delle tecnologie di intelligenza artificiale. Con la crescente adozione di queste soluzioni da parte di aziende di diversi segmenti, si apre un’opportunità senza precedenti per trasformare le interazioni, ottimizzare i processi e offrire soluzioni più personalizzate.
Iniziative open source come LLaMA di Meta, insieme all’implementazione di modelli più piccoli come SLM, stanno democratizzando l’accesso all’intelligenza artificiale. Questi approcci consentono anche alle organizzazioni più piccole di beneficiare della potenza dei modelli linguistici, contribuendo a un ecosistema in cui prosperano l’innovazione e la collaborazione. L’Intelligenza Artificiale diventa così sempre più accessibile e applicabile, affermandosi come un nuovo e prospero mercato nel settore dell’informatica.
( MIT Technology Review)

