In November 2022, OpenAI transformed the Artificial Intelligence landscape by launching ChatGPT, an advanced chatbot system based on the Transformer architecture, which was introduced by Google in 2017 in the influential “Attention is All You Need” paper. This architecture revolutionized the field of natural language processing by introducing the attention mechanism, allowing models to identify complex contextual relationships between words, resulting in more coherent and relevant responses.
Currently, the platform has 100 million users, and the AI market continues to expand, with new forms and applications continually emerging. This article aims to clarify the panorama of the AI market in the post-ChatGPT scenario, highlighting the innovations, trends and opportunities that have emerged since the launch of this revolutionary system.
The popularization of large-scale language models (LLM)
ChatGPT is classified as a Large Language Models (LLM), a technology of models trained with vast amounts of data to generate natural language responses. With the rapid adoption of users with different profiles, other large companies also began to position themselves in the market, leading the LLM sector to take shape and expand quickly.
The following year, in 2023, Google launched Bard, a chatbot based on its own model that also uses the Transformer architecture. Subsequently, other more advanced models emerged, such as Gemini, also from Google, Claude, from Anthropic, Ernie, from Baidu, and Grok, from Elon Musk. All of these models are proprietary and were developed with the aim of capturing a share of the market. However, due to the differences in the characteristics of the models and the diverse demands of the market, each of them ended up specializing in different niches and applications.
For example, Claude was developed with a strong emphasis on calibrating the ethics of responses, seeking to avoid any undue influence on users. Ernie, in turn, was designed to operate within Chinese applications, ensuring compliance with local regulations and avoiding external political interference. Grok was integrated into Elon Musk’s new application, X (formerly Twitter), with the aim of providing responses and interactions directly on the platform.
Open Source Initiatives
Another major player, Meta (formerly known as Facebook), decided to go in the opposite direction of the proprietary AI market, investing in the community with the launch of LLaMA (Large Language Model Meta AI), an open source model. Recognizing the challenges of gathering a large mass of training data, such as that used in ChatGPT, and the high processing cost of training large-scale models, Meta released a specific version, Meta LLaMA 3.1, with a pre-built base. trained and available to the public.
This approach allowed developers to have direct access to the source code and be able to train their own custom versions of the model. The initiative fostered the emergence of a series of derivative models, encouraging collaboration and the advancement of AI technologies in open environments. With this, Meta contributed to a more inclusive and innovative development community, expanding access to advanced AI technologies. Open source alternatives quickly gained traction. Models such as Dolly, developed by Databricks, and Mistral were introduced as affordable options for developers who needed flexible and customizable LLMs, without the high costs of closed and proprietary models. This has allowed companies and researchers to develop LLMs tailored to their specific needs, enabling more targeted and specialized uses.
While proprietary models are often designed for generic uses, many companies with expertise in specific areas choose to train their own models to avoid exposing sensitive data to third parties, such as OpenAI. The open source market has therefore gained support from these companies, who often establish their own AI data centers and train unique models to meet their security and specialization demands.
The role of Fine-Tuning: incorporating specialized knowledge
One of the main innovations in the use of LLMs is the possibility of fine-tuning. This process consists of using the already trained database, such as GPT-4 or LLaMA 3.1, with additional data specific to a particular application. It is an especially advantageous approach in contexts that require specialized terminology or in-depth knowledge, such as in healthcare, law or finance. With fine-tuning, the model “learns” industry-specific patterns and vocabulary, becoming more accurate and efficient when answering questions or performing tasks related to that domain.
Companies and organizations have demanded many fine-tuning services, says Gustavo Zaniboni, CAIO at Ananque, “fine-tuning makes it possible to train language models with internal data, creating AI systems that better understand the institution’s specific processes and contexts”. This technique significantly increases the relevance of answers and transforms LLMs into practical and powerful tools for commercial use, expanding their value in business applications.
Context, Tokens and RAG
One of the parameters that directly impacts the quality of responses generated by large-scale language models (LLMs) is the context window, which allows the model to retain relevant information about the topic discussed throughout the conversation. This context acts as a short-term memory, enabling the LLM to have a richer and more accurate understanding of the query. As the context increases, the number of tokens (language processing units) used also increases, which demands more computational resources and, as a result, makes processing more expensive.
For the companies providing the service, more tokens mean more profit, however, for the user, it became increasingly costly to upload a specialized token database. Trying to bring together the best for both sides, intermediate technology began to be used.
Information recovery with RAG: bringing together the best of both worlds
The intermediate technology serves for increased generation via data recovery, and is called RAG (Retrieval-Augmented Generation) in English. It combines language models with information retrieval mechanisms. The RAG approach allows the model to access and embed specific data directly into the prompt, querying databases without the need to send all tokens with each request. This approach optimizes costs, as it reduces the volume of data processed per query, while maintaining the accuracy and relevance of responses.
The RAG technique also solves another problem, the fact that LLM has a pre-trained and static database, which ends up becoming outdated over time. The RAG database can include external data and maintain the most current and relevant knowledge for longer, until new major training is carried out.
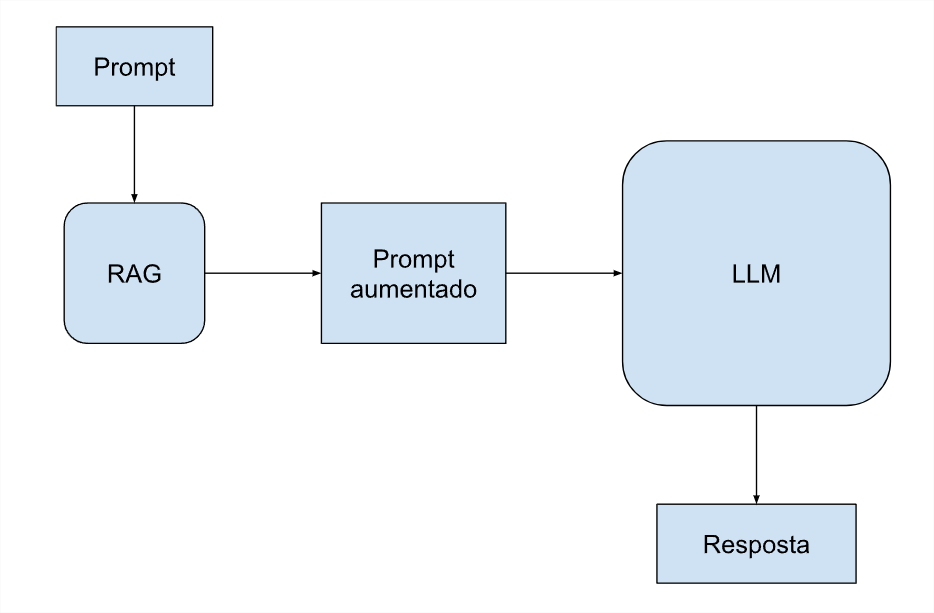
It is important to note that many specialized professionals still believe that, for individuals or end users, ChatGPT is still the best LLM for most tasks, as stated by Elisa Terumi, PhD in IT from PUC-P. “Proprietary models, such as those in the GPT-4 family, are generally larger and more robust, trained on larger data volumes and with a greater number of parameters.
They also undergo advanced tuning techniques, such as reinforcement learning with human feedback (RLHF), improving their ability to generate more natural and contextualized responses. In this way, models from the GPT family generally present superior performance in many tasks.” However, for corporate use, the challenges are different, covering aspects such as data sensitivity and high processing and internet infrastructure costs. These issues require specific solutions and strategic approaches to ensure safety, efficiency and economic viability.
Corporate applications with Small Language Model
A company that wants to offer a specialized service with its own data can benefit from using SLM (Small Language Model). “This approach is growing in the market”, says Danilo Santos, founder of Servicedesk Brasil, mainly driven by the growing number of AI specialists and consultants. To protect sensitive data and significantly reduce query costs, many companies are choosing to hire an AI professional to install an LLM in their own data center and train it from scratch.
Generally, the database of these companies is not as extensive as that used by large technology companies, which is why the technique is called SLM (Small instead of Large). Although these models involve less data, they are capable of delivering relevant and accurate information, even if they lack the fluidity of chat language found in more robust LLMs, which are designed to meet the demands of individual end users. This strategy allows companies to leverage their internal information effectively while ensuring data security and confidentiality.
Artificial Intelligence Overview
Artificial Intelligence is definitely in the spotlight after the launch of ChatGPT. LLMs are making a significant impact across all industry and service sectors. Due to its enormous potential, investments in this area have grown rapidly, resulting in a constant evolution of AI technologies. With the increasing adoption of these solutions by companies from different segments, an unprecedented opportunity is opening up to transform interactions, optimize processes and offer more personalized solutions.
Open source initiatives like Meta’s LLaMA, along with the implementation of smaller models like SLM, are democratizing access to AI. These approaches allow smaller organizations to also benefit from the power of language models, contributing to an ecosystem where innovation and collaboration thrive. Thus, Artificial Intelligence becomes increasingly accessible and applicable, establishing itself as a new and prosperous market in the area of information technology.
( MIT Technology Review)

