Anthropic announced two new AI models that it claims represent a big step towards making AI agents really useful.
AI agents trained in Claude Opus 4, the most powerful version of the company to date, raise the standard of what these systems are capable of doing, facing difficult tasks for prolonged periods and responding more usefully to user instructions, according to the company.
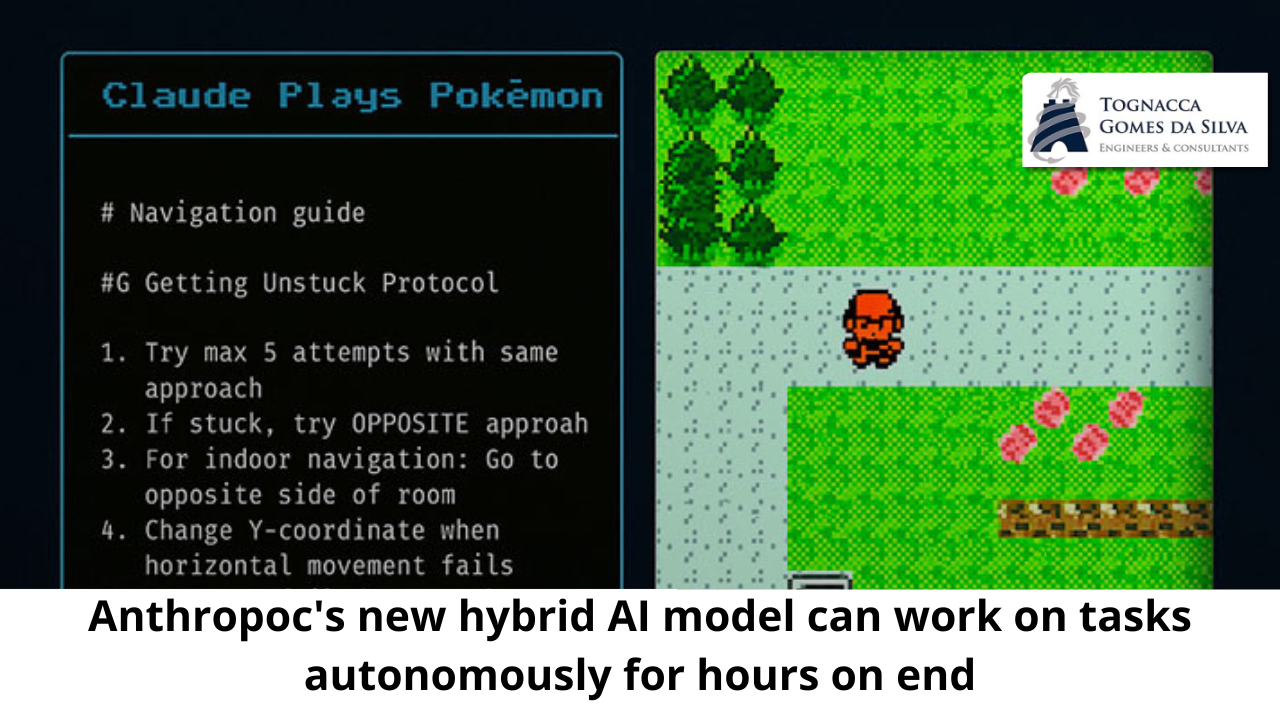
Claude Opus 4 is designed to perform complex tasks that involve performing thousands of steps over several hours. For example, he created a guide for the Pokémon Red video game while playing for more than 24 hours straight. The company’s most powerful system previously, the Claude 3.7 Sonnet, could play for only 45 minutes, says Dianne Penn, research product leader at Anthropic.
Similarly, the company says that one of its customers, the Japanese technology company Rakuten, recently used Claude Opus 4 to code autonomously for almost seven hours in a complicated open source project.
Anthropic achieved these advances by improving the model’s ability to create and maintain “memory files” to store key information. This improved ability to “remember” makes the version better at completing longer tasks.
“We consider this new generation of models a paradigm jump: from assistants to real autonomous agents,” says Penn. “While you still need to give a lot of real-time feedback and make all the key decisions for AI assistants, an agent can make these key decisions on their own. This allows humans to act more as managers or judges, instead of having to follow these systems at every step.”
Although the Claude Opus 4 is limited to Anthropic paying customers, a second model, the Claude Sonnet 4, will be available to users of both the paid and free versions. Opus 4 is being marketed as a powerful and large version for complex challenges, while Sonnet 4 is described as an intelligent and efficient platform for daily use.
Both new platforms are hybrid, which means they can offer a quick response or a deeper, more thoughtful response, depending on the nature of the request. While calculating an answer, both systems can perform online searches or use other tools to improve their output.
( fontes: MIT Technology Review)